Runs
Overview
A run is an instance of a workflow. Runs record each workflow instance's input, trigger, node, and result.
You can view a list of all workflows for a Space by going to the Global Workflow > Runs console.
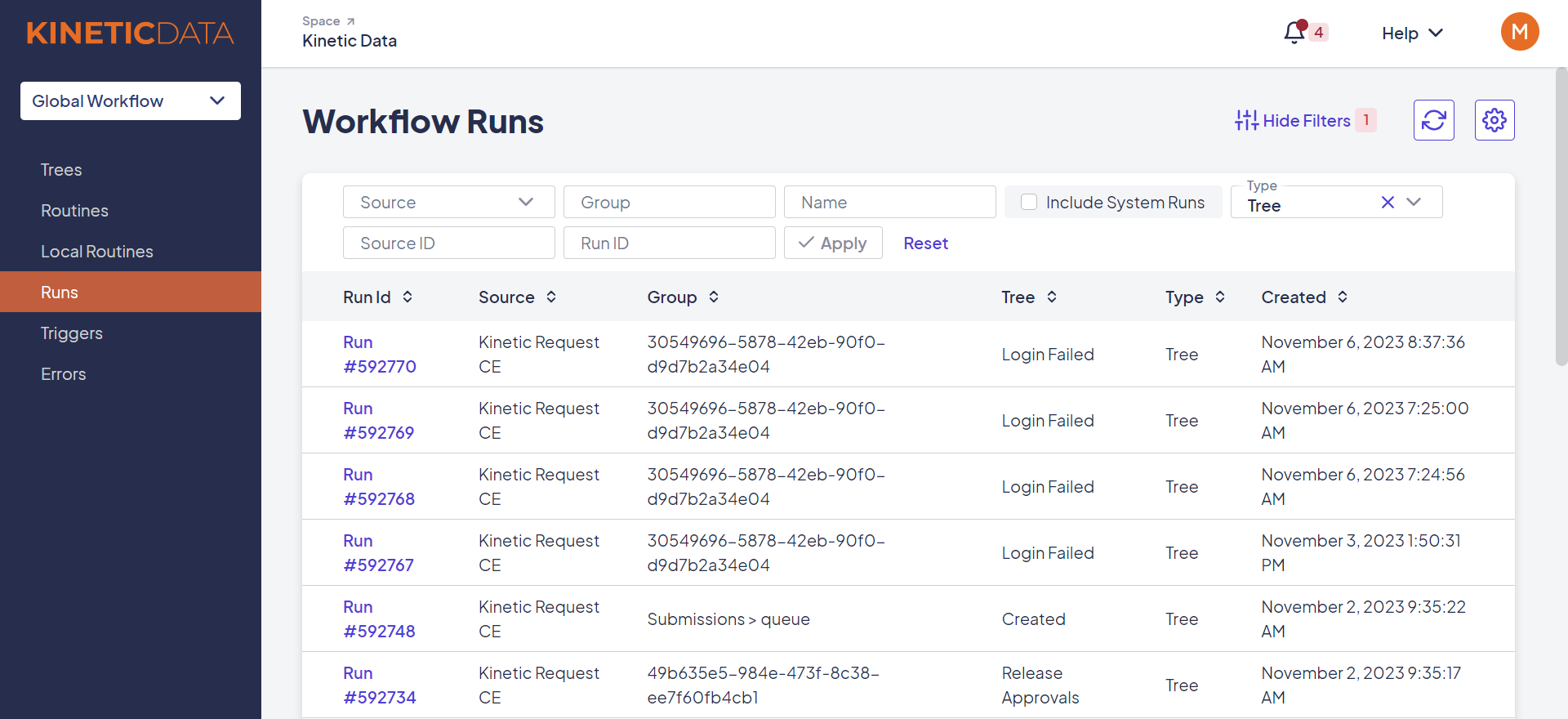
The Runs page in the Global Workflow console
The most recent runs are displayed first. You can also use the filters at the top of the console to limit which runs are displayed. In the screenshot above, the list of runs is limited to Tree-type runs.
Note: Create trees and routines do not have submission IDs.
You can view information for an individual run by selecting a Run Id in the Workflow Runs console.
- By opening the Workflow Builder (either from a workflow or a form) and clicking the clock button

- By searching from the Runs pane in Workflow Builder
- By going to the Global Workflow > Runs console
To access a run from a specific workflow, click the clock button on the left side of the Workflow Builder. You can access the Workflow Builder from the Workflows console or a form.
This tab shows a list of the runs, beginning with the most recent. Options to filter the list are available at the top of the console.
Reading Run Details
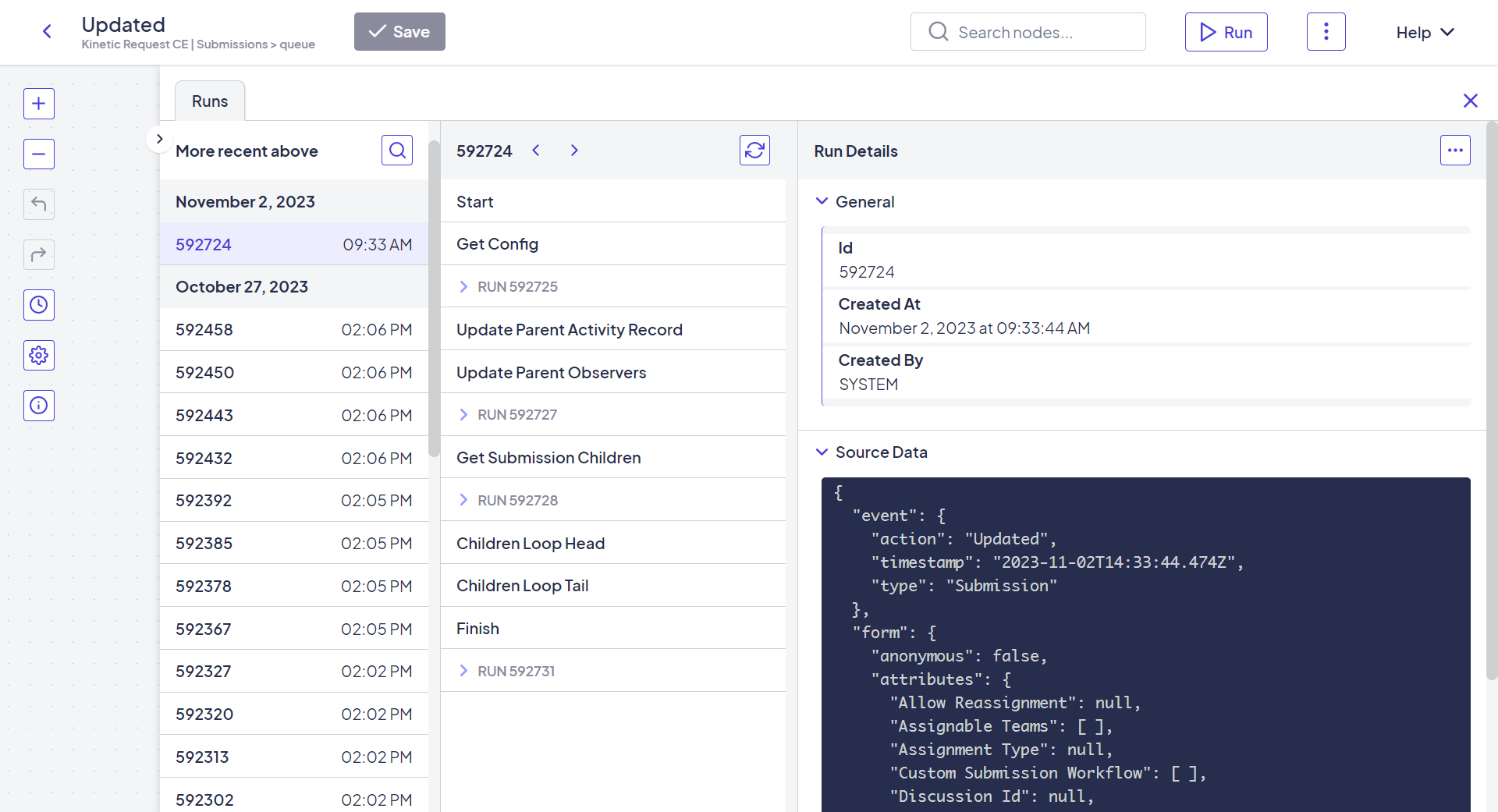
Viewing Run details in the Run Explorer
The Run Explorer displays all information related to the run, from basics like the run number to detailed information like the duration of an individual task in milliseconds. Part of using the Run Explorer effectively is knowing what information it presents and how you might be able to use that information. The Runs Explorer is divided into the following panes:
- A list of all runs for the workflow
- A full representation of a workflow run, including any nested workflows
- Details for the portion of the run selected in the middle pane
Run List
Along with displaying all runs for a workflow, the Run List lets you search the workflow for a specific run. To do so, click  Search Runs and enter a run date, Run Id, or Source Id.
Search Runs and enter a run date, Run Id, or Source Id.
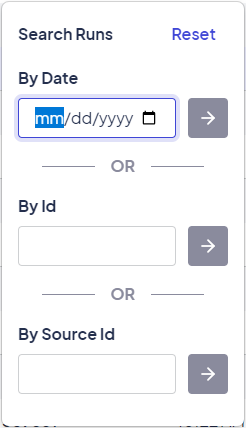
The search options available in the Run Explorer
Note: If you enter a valid Id that does not belong to the workflow you are currently viewing, no results will be returned.
The list of runs does not update automatically. Click  Refresh Runs to update the list.
Refresh Runs to update the list.
Run Stages
The middle pane lists each stage of the run, with any errors appearing at the top of the pane. You can update the run information by clicking Refresh Runs.
Nested runs are displayed in expandable sections. Click a workflow node to populate the rightmost pane with additional details.
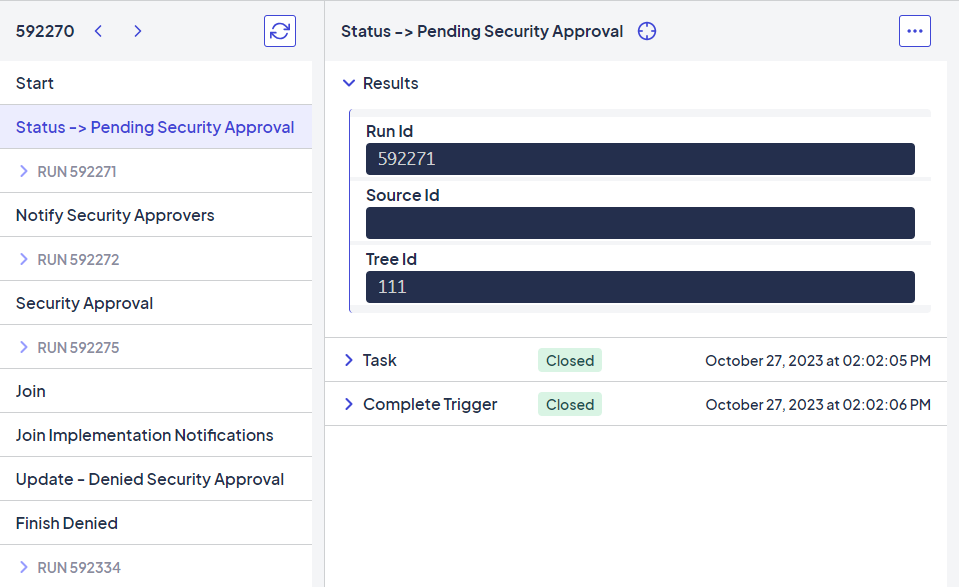
Selecting a workflow node displays more details in the rightmost pane
Run Details
The rightmost pane goes into full detail for each stage of the run. The following options are available at the top of the pane:
- The
 Locate option selects the relevant workflow node in the Workflow Builder.
Locate option selects the relevant workflow node in the Workflow Builder. - The
 Open option lets you open the run information for a nested node in a new tab.
Open option lets you open the run information for a nested node in a new tab. - The
 Actions menu lets you edit run results, repeat the run, or create a manual trigger for the run (depending on the event selected).
Actions menu lets you edit run results, repeat the run, or create a manual trigger for the run (depending on the event selected).
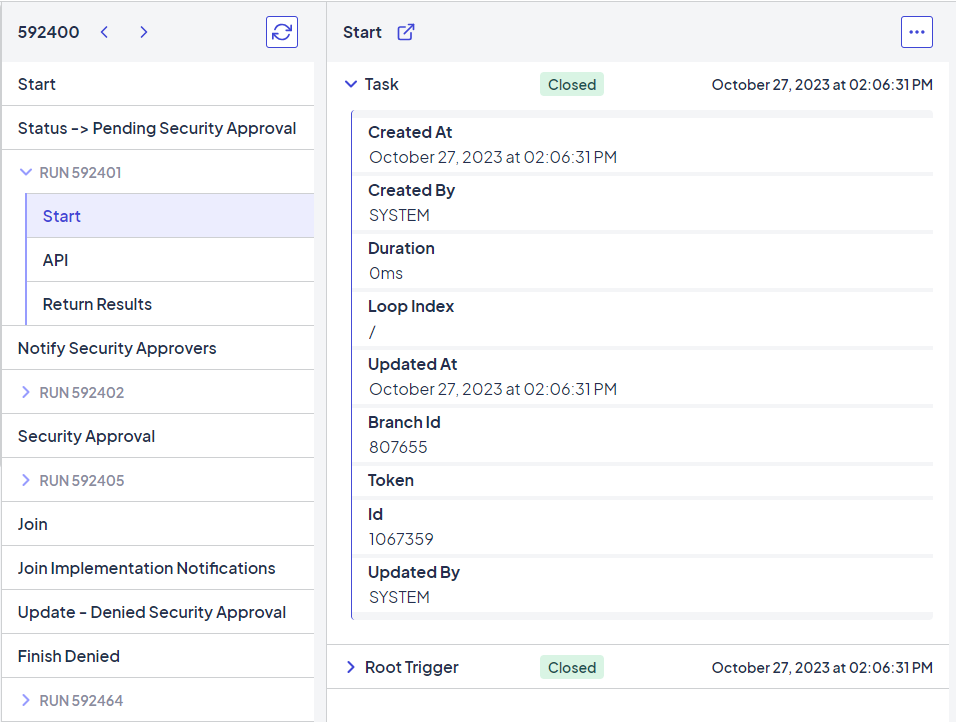
Example of a nested node that can be opened in a new tab
The Run Again option opens the New Run modal window prepopulated with the inputs from the existing run. This lets you test updates in the tree without having to recreate the submission on the front end.
The Create Manual Trigger option lets you "restart" branches of execution that did not fire because a connector incorrectly evaluated to false. A manually created trigger cannot be used to re-run tasks that have already been executed. This functionality can cause unintended consequences and should be used with caution.
Below the menu options, nodes are further separated into tasks, inputs, and triggers.
Tasks
Tasks reflect the nodes in the workflow that are doing a piece of work. At minimum, these display a task Id, an updated time, and a branch Id. The most useful information is whether the task was executed and at exactly what time, particularly compared to the other items in the run.
Many tasks will also contain results. There are two kinds of results. Some results will be there as soon as the task runs, and deferred results will be there once a deferred task is complete. Both regular and deferred results are displayed in the Results section of the task in the run.
The results of a task are editable. This may be necessary if data issues contribute to an error. Any edits to task results are audited.
Tasks generally have three statuses: New, Deferred, and Closed.
- New: The task has not yet been executed.
- Deferred: The initial actions in the task have been executed, and the task is awaiting an update or complete trigger.
- Closed: The task has completed its execution.
Deferred Tasks
Deferred tasks pause the workflow until they receive a trigger indicating that the task is complete. As such, if there is an open deferred task, it is often the last node displaying in a run. The workflow is waiting for it to be completed before moving on.
If a deferred run results in another child node, you can open that node in a new window by clicking the Open button.
Loops
Loops generally add a lot of triggers and tasks to a timeline. The important keys are this:
- If you only see a head and tail, the head evaluation determined that there were no instances of the loop to execute.
- Multiple instances of a loop are labeled as iterations and numbered sequentially. You can expand an interaction to select and view details for the loop.
Inputs
The inputs tab displays the input provided for this run. For trees, this is source data; for routines, this is individual inputs. Either way, as with results, this is editable. Any edits to this are audited as well.
Triggers
Triggers are what tell the engine to do something, such as start a workflow, pick back up a deferred task, or retry an error.
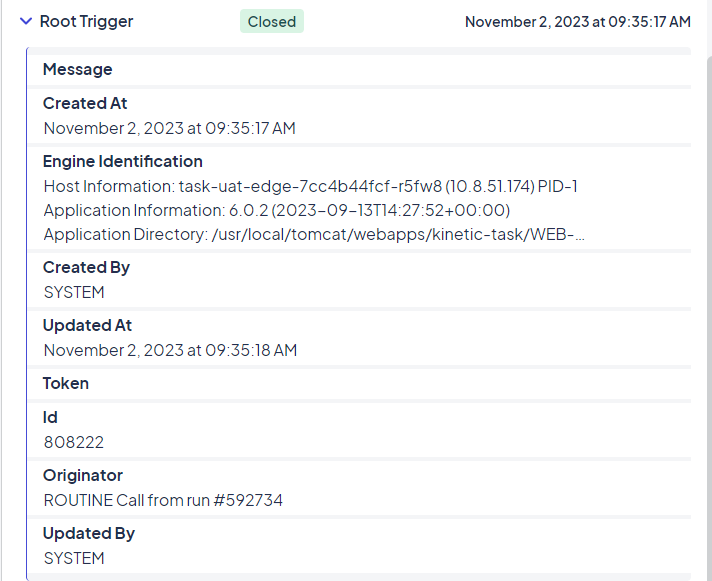
Example of a Closed trigger
Expanding the trigger details gives you the origination information for the run that sent or created the trigger. This helps you determine where a routine was triggered or where a task was completed.
The Engine Identification heading provides information on the originating task engine. This information makes it easy to determine where an issue occurred when multiple engines are in play (for example, when old engines exist as backups or when one specific production server is causing an issue.)
Triggers generally have three statuses: New, Closed, and Failed.
- New: The trigger is in the system but not yet picked up by the engine.
- Closed: The trigger has been successfully executed by the engine.
- Failed: The trigger encountered an error when trying to execute.
Errors
Errors inside the run will accompany a New Task and a Failed Trigger.
The error provides the error number with a link to the full error information, the type of error, and a summary of the error. Generally, you must follow the link and go to the full error page to troubleshoot and resolve the error.
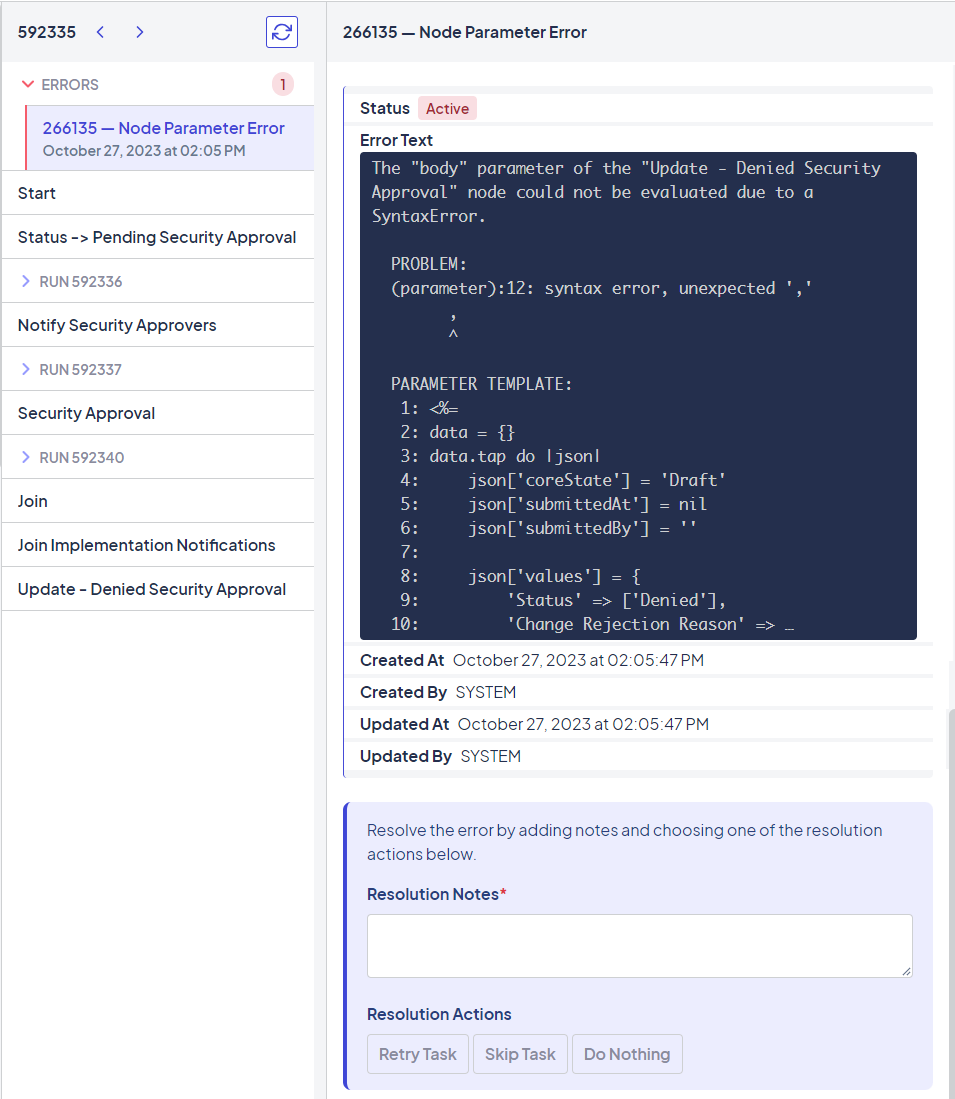
Example of an error in a workflow node and the available resolution options
Updated 5 months ago